by Dr A. Mesut Erzurumluoğlu | Principal Bioinformatician at Bicycle Therapeutics (formerly at Boehringer Ingelheim, and Univs. of Cambridge, Leicester & Bristol) – blogging since 2006. All views mine unless stated otherwise
It is not the strongest of the species that survives, nor the most intelligent that survives. It is the one that is most adaptable to change – attributed to Charles Darwin
“How did you get accepted to Cambridge?”
I saw a tweet a while ago which said something along the lines of: “If you’ve been asked the same question three times, you need to write a blog post about it”. I get asked about how I got my current postdoc job at the University of Cambridge all the time. Therefore, I decided to write this document to provide a bit of a backstory as I did many things over the years which – with a bit of luck – contributed to this ‘achievement’.
It is a long document but hopefully it will be worth reading in full for all foreign PhD students, newPostdocs and undergraduates who want an introduction to the world of academia in the UK. I wish I could write it in other languages (for a Turkish version click here) to make it as easy as I can for you, but I strived to use as less jargon as possible. Although there is some UK-specific information in there, the document is mostly filled with general guidance that will be applicable to not just foreign students or those who want to study in the UK, but all PhD students and new Postdocs.
I can only hope that there are no errors and every section is complete and fully understandable but please do contact me for clarifications, suggestions and/or criticism. I thank you in advance!
To make a connection between academia in the UK and the quote attributed to Darwin above, I would say being very clever/intelligent is definitely an advantage in academia but it is not the be-all and end-all. Learning to adapt with the changing landscape (e.g. sought-after skills, priorities of funders and PIs), keeping a good relationship with your colleagues and supervisors, and being able to sell yourself is as, if not more important. Those who pay attention to this side of academia usually make things easier for themselves.
I hope the below document helps you reach the places you want to reach:
A really useful document for UK PhD students – particularly those from abroad. It's Mesut's personal take, focused on genepi, but there is some really useful stuff here. https://t.co/V4sEy5vXMQ
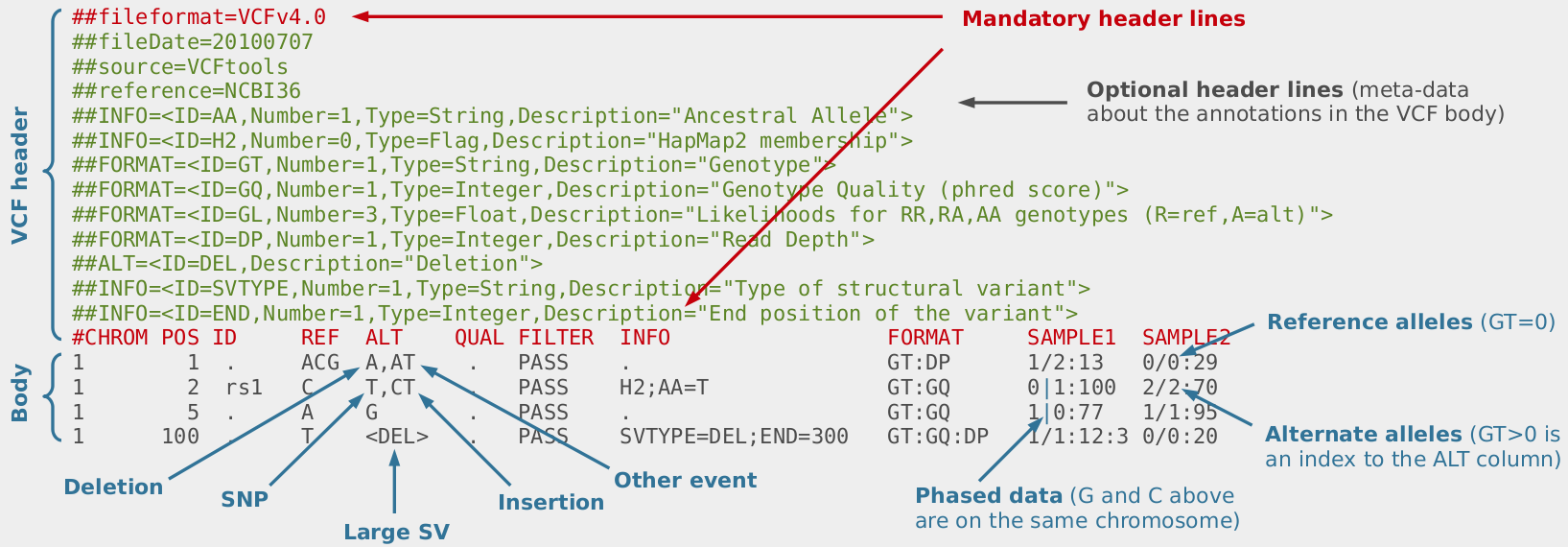
An example output from AutoZplotter using whole-exome sequencing data – used to identify the Primary ciliary dyskinesia causal gene, CCDC151, in Alsaadi and Erzurumluoglu et al, 2014 (read this paper’s story here). The green and red dots correspond to heterozygous and homozygous calls (for the alternative allele), respectively. The continuous blue lines correspond to the probability that the observed sequence of genotypes is not autozygous (e.g. close to zero means likely to be an autozygous region). LRoH: Long runs of homozygosity. NB: This image has been edited to ensure confidentiality/anonymity of the participant. Some LRoHs have been shortened or extended for this reason. If you’re thinking of using an AutoZplotter image in a paper, do not share genome-wide figures but maybe consider using chromosome-wide ones
When analysing whole-exome or whole-genome sequencing (or dense SNP chip) data obtained from consanguineous individuals with a rare Mendelian disease, the disease causal mutation usually lies within an autozygous region (characterised by long runs of homozygosity, LRoH, which are generally >5Mb). Thus checking whether any candidate genes overlap with an LRoH can substantially narrow region(s) of interest. There are several tools which can identify LRoHs such as Plink, AutoSNPa and AgilentVariantMapper. However, they all require their own formats and considerable computational knowledge; and also struggle to identify regions that are shorter than 5Mb. Thus, we wrote AutoZplotter, a user-friendly python script which plots the heterozygosity/homozygosity status of variants in a VCF file to allow for quick visualisation and manual identification of regions that have longer stretches of homozygosity than would be expected by chance.
AutoZplotter accepts the VCF format – which is the standard format for storing genetic variation data from NGS platforms. Image Source URL: bioinf.comav.upv.es
The input format of AutoZplotter is VCF, thus it will be suitable for any type of genetic data (e.g. SNP array, WES, WGS) and from any species.
To download latest version of AutoZplotter, click here (directs to ResearchGate). If you found AutoZplotter helpful in anyway, please cite Erzurumluoglu AM et al, 2015.
References:
Erzurumluoglu AM et al, 2015. Identifying Highly Penetrant Disease Causal Mutations Using Next Generation Sequencing: Guide to Whole Process. BioMed Research International. Volume 2015 (2015), Article ID 923491
Alsaadi MM and Erzurumluoglu AM et al, 2014. Nonsense Mutation in Coiled-Coil Domain Containing 151 Gene (CCDC151) Causes Primary Ciliary Dyskinesia. Human Mutation. Volume 35, Issue 12. Pages 1446–1448
Erzurumluoglu AM et al, 2016. Importance of Genetic Studies in Consanguineous Populations for the Characterization of Novel Human Gene Functions. Volume 80, Issue 3. Pages 187–196
Erzurumluoglu AM, 2015. Population and family based studies of Consanguinity: Genetic and Computational approaches. PhD Thesis. University of Bristol
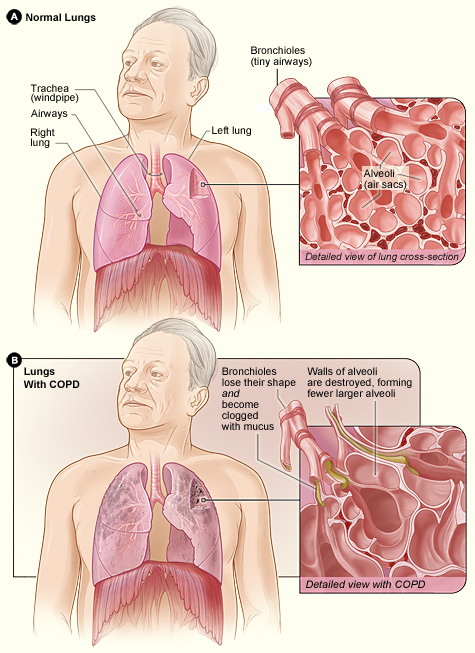
Difference between the lung of a COPD patient and an unaffected one. Image taken from the NHLBI website (one of the leading institutes in providing information on various diseases; click on image to access the source)
Many of us will either suffer or have a relative/friend who suffers from a disease called Chronic Obstructive Pulmonary Disease (COPD, click on link for details) which is a progressive respiratory disease characterised by decreasing lung function (struggling to inhale/exhale air, irreversible airflow obstruction), very likely accompanied by chronic infections. COPD has a prevalence of over 2% in the UK population (corresponding to approx. 1 million in the UK, probably a lower bound estimate due to many undiagnosed cases; this figure is approx. 16 million in the USA) and is currently the third biggest killer in the world (only behind cancers and heart-related diseases) – costing the lives of millions (in the USA alone, number of deaths attributed to COPD is over 100 thousand); and the health services, billions of pounds.
Contrary to the well-known genetic disorders such as Cystic Fibrosis and Huntington’s disease, which are diseases caused entirely by a person’s genetic makeup and caused by mutations in a single gene, COPD is a (very!) complex disease with many genes and environmental factors (e.g. smoking, pollutants) contributing to the development/progression of the disease. This complexity makes it much harder to dissect the causes and find potential (genetic) targets for cures or therapies. However, we do know that smoking is by far the biggest risk factor with up to 90% of those who go on to develop clinically significant COPD being smokers. But only a minority (<25%) of all smokers develop COPD, indicating the strong role genetics can play in the progression of this disorder. Also not all COPD patients are smokers (up to 25% in some populations), indicating that – at least in some patients – genetics can play a rather determining role. I must stress that all the statistics I provide here can vary considerably from population to population due to different lifestyles and genetic backgrounds.
I – together with a large group of collaborators – search for genetic predictors of lung function, which helps us to identify which individuals are more likely to develop the disease and potentially understand the underlying biology/pathology of respiratory diseases such as COPD and asthma, and related traits such as smoking behaviour. To do this, we carry out what is called a genome-wide association study (GWAS, click on link for details), where we obtain the genetic data (millions of data points) from tens of thousands of COPD (or asthma) patients and ‘controls’ (people with normal lung function). To ensure that our results are not biased by different ethnicities, life styles and related individuals, we collect all the relevant information about the participants and make sure that we control for them in the statistical models that we use. GWASs have been extremely successful in the identification of successful targets for other diseases and have led to the field of Genetic Epidemiology (GE, click on link for details) to come to the fore of population-based medicine. GE requires extensive understanding of Statistics (needed to make sense of the very large datasets), Bioinformatics (application of computer software to the management of large biological data), Programming (needed to change data formats, manage very large data), Genetics (needed for interpretation of results) and Epidemiology (branch of medicine which deals with how often diseases occur in different groups of people, and why); thus requires inter-disciplinary collaborations.
GWAS results are traditionally presented with a Manhattan plot (due to its resemblance of the city’s skyline) where the genetic variants corresponding to the dots above the top grey line (representing P-values less than 5e-8 i.e. 0.00000005) are usually followed up with additional studies to validate their plausibility. Image taken from Wikipedia (click on image to access source)
The inferences we make from these studies can shed light in to which genes and biological pathways play key roles in causing COPD. We then follow up these newly identified genes and pathways to analyse whether there are molecules which could be used to target these and be potential drugs for treating COPD patients. Our results can be of immense help to Pharmaceutical companies (and ultimately to patients), as many clinical trials initiated without genetic line of evidence have failed, costing the public and these companies billions of pounds.
As smoking is the biggest risk factor for respiratory diseases like COPD, I am – also with the contribution of many collaborators – in the process of analysing whether some people are more likely to start smoking, stop after starting, and smoke more than usual when they start smoking. The results can have huge implications as many people struggle to stop smoking, and when they do, research suggests that up to 90% (figure differs between populations) of them start to smoke again within the first year after quitting. Smoking is not only a huge contributor to the risk of developing COPD, but also to lung (biggest killer amongst all cancers), mouth, throat, kidney, liver, pancreas, stomach and colon cancer (not an exhaustive list). In the UK alone, these cancers cause the slow and painful death of tens of thousands, alongside a huge psychological and financial burden on the families and public resources.
The “lung” and the short of it (stealing a phrase thought up by my colleagues at the University of Leicester, click on link to see who they are) is that COPD is a disease that is going to affect many of us, and any useful finding which leads to cures and/or therapies could increase the life years of COPD patients and affect the lives of thousands of people directly, and millions indirectly (e.g. families of COPD sufferers, cost to the NHS). Finding targets to help people stop smoking can potentially have even bigger implications as many continue to smoke, despite huge efforts and funding allocated to smoking prevention and cessation.
A nice TED talk about the world of Data science and Genetic Epidemiology
Ben 12 yaşındayken (2000) ailecek İngiltere'ye taşındık ve ingilizcem neredeyse sıfırdı. Bunu duyan (Karen Holman adında) Sınıf Öğretmenim, kendimi evimde hissedeyim diye tüm arkadaşlarıma Türkçe cümleler dağıtmış. Sınıfa girer-girmez arkadaşlarımın hepsi bana "Hoşgeldin" dediler