by Dr A. Mesut Erzurumluoğlu | Principal Bioinformatician at Bicycle Therapeutics (formerly at Boehringer Ingelheim, and Univs. of Cambridge, Leicester & Bristol) – blogging since 2006. All views mine unless stated otherwise
It is not the strongest of the species that survives, nor the most intelligent that survives. It is the one that is most adaptable to change – attributed to Charles Darwin
“How did you get accepted to Cambridge?”
I saw a tweet a while ago which said something along the lines of: “If you’ve been asked the same question three times, you need to write a blog post about it”. I get asked about how I got my current postdoc job at the University of Cambridge all the time. Therefore, I decided to write this document to provide a bit of a backstory as I did many things over the years which – with a bit of luck – contributed to this ‘achievement’.
It is a long document but hopefully it will be worth reading in full for all foreign PhD students, newPostdocs and undergraduates who want an introduction to the world of academia in the UK. I wish I could write it in other languages (for a Turkish version click here) to make it as easy as I can for you, but I strived to use as less jargon as possible. Although there is some UK-specific information in there, the document is mostly filled with general guidance that will be applicable to not just foreign students or those who want to study in the UK, but all PhD students and new Postdocs.
I can only hope that there are no errors and every section is complete and fully understandable but please do contact me for clarifications, suggestions and/or criticism. I thank you in advance!
To make a connection between academia in the UK and the quote attributed to Darwin above, I would say being very clever/intelligent is definitely an advantage in academia but it is not the be-all and end-all. Learning to adapt with the changing landscape (e.g. sought-after skills, priorities of funders and PIs), keeping a good relationship with your colleagues and supervisors, and being able to sell yourself is as, if not more important. Those who pay attention to this side of academia usually make things easier for themselves.
I hope the below document helps you reach the places you want to reach:
A really useful document for UK PhD students – particularly those from abroad. It's Mesut's personal take, focused on genepi, but there is some really useful stuff here. https://t.co/V4sEy5vXMQ
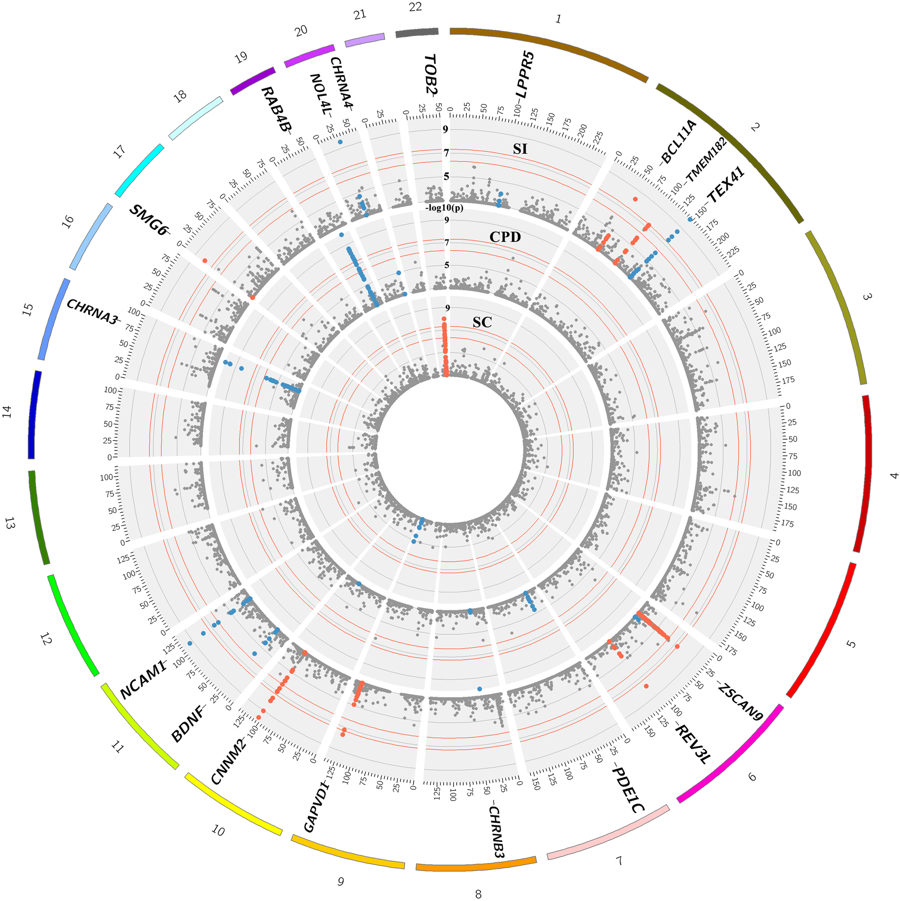
A ‘Circos’ plot (with three concentric circular ‘Manhattan’ plots) presenting results from our latest genetic association study of smoking behaviour – showing some (not all) regions in our genome that are associated with smoking behaviour (Erzurumluoglu, Liu, Jackson et al, 2019). SI: Smoking initiation – whether they smoke or not; CPD: Cigarettes per day – how many cigarettes do they smoke per day; SC: Smoking cessation – whether they’ve stopped smoking after starting. Labels in the outer circle show the name of the nearest gene to the identified variants. X-axis: Genomic positions of the variants in the human genome (chromosome numbers, 1-22, in the outer circle), Y-axis: Statistical significance of the genetic variants in this study – higher the peak, greater the significance. Red peaks are the newly identified regions in the genome, and the blue ones were identified by previous groups. Image source: Molecular Psychiatry
I believe that all scientists should be bloggers and that they should spare some thought and time to explain their research to interested non-scientists without using technical jargon. This is going to be my attempt at one; hopefully it’ll be a nice and short read.
We’ve just published a paper in one of the top molecular psychiatry journals (well, named Molecular Psychiatry 🙂 ) where we tried to identify genetic variants that (directly or indirectly) affect (i) whether a person starts smoking or not, and once initiated, (ii) whether they smoke more. The paper is titled: Meta-analysis of up to 622,409 individuals identifies 40 novel smoking behaviour associated genetic loci. It is ‘open access’ so anyone with access to the internet can read the paper without paying a single penny.
If you can understand the paper, great! If not, I will now try my best to explain some of the key points of the paper:
Why is it important?
Smoking causes all sorts of diseases, including respiratory diseases such as chronic obstructive pulmonary disease (which causes 1 in 20 of all deaths globally; more stats here) and lung cancer – which causes ~1 in 5 of all cancer deaths (more stats here). Therefore understanding what causes individuals to smoke is very important. A deeper understanding can help us develop therapies/interventions that help smokers to stop and have a massive impact on reducing the financial, health and emotional burden of smoking-related diseases.
Genes and Smoking? What!?
There are currently around fifty genetic variants that are identified to be associated with various smoking behaviours and we identified 40 of them in our latest study, including two on the X-chromosome which is potentially very interesting. There are probably hundreds more to be found*. So, it’s hard to comprehend but yes, our genes – given the environment– can affect whether we start smoking or not, and whether we’ll smoke heavier or not. This is not to say our genes determine whether we smoke or not so that we can’t do anything about it.
There are three main take-home messages:
1- I have to start by re-iterating the “given the environment” comment above. If there was no such thing as cigarettes or tobacco in the world, there would be no smoking. If none of our friends or family members smoked, we’re probably not going to smoke no matter what genetic variants we inherit. So the ‘environment’ you’re brought up in is by far the most important reason why you may start smoking.
2- I have to also underline the term “associated“. What we’re identifying are correlations so we don’t know whether these genetic variants are directly or indirectly affecting the smoking behaviour of individuals – bearing in mind that some might be statistical artefacts. Some of the genetic variants are more apparently related to smoking than others though: for example, variants in genes coding for nicotine receptors cause them to function less efficiently so more nicotine is needed to induce ‘that happy feeling‘ that smokers get. Other variants can directly or indirectly affect the educational attainment of an individual, which in turn can affect whether someone smokes or not. I’d highly recommend reading the ‘FAQ’ by the Social Science Genetic Association Consortium (link below) which fantastically explains the caveats that comes with these types of genetic association studies.
3- Last but not least, there are many (I mean many!) non-smokers who have these genetic variants. I haven’t got any data on this but I’m almost 100% sure that all of us have at least one of these variants – but a large majority of people in the world (~80%) don’t smoke.
Closing remarks
To identify these genetic variants, we had to analyse the genetic data of over 620k people. To then identify which genes and biological pathways these variants may be affecting, we queried many genetic, biochemical and protein databases. We’ve been working on this study for over 2 years.
Finally, this study would not be possible (i) without the participants of over 60 studies, especially of UK Biobank – who’ve contributed ~400k of the total 622k, and (ii) without a huge scientific collaboration. The study was led by groups located at the University of Leicester, University of Cambridge, University of Minnesota and Penn State University – with contribution by researchers from >100 different institutions.
It will be interesting to see what, if any, impact these findings will have. We hope that there will be at least one gene within our paper that turns out to be a target for an effective smoking cessation drug.
Meta-analysis of up to 622,409 individuals identifies 40 novel smoking behaviour associated genetic loci – by Erzurumluoglu, Liu and Jackson et al https://t.co/vTxzjOPlpm
*in fact we know that there is another paper in press that has identified a lot more associations than we have
Great to see this published today in Molecular Psychiatry. A huge team effort, using data from 60 studies and @uk_biobank, to further our understanding of the biology behind #tobacco#addiction. https://t.co/0sGD3Q40yr
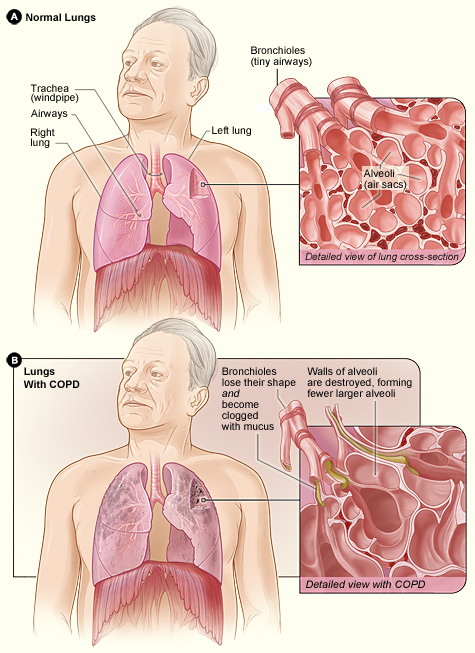
Difference between the lung of a COPD patient and an unaffected one. Image taken from the NHLBI website (one of the leading institutes in providing information on various diseases; click on image to access the source)
Many of us will either suffer or have a relative/friend who suffers from a disease called Chronic Obstructive Pulmonary Disease (COPD, click on link for details) which is a progressive respiratory disease characterised by decreasing lung function (struggling to inhale/exhale air, irreversible airflow obstruction), very likely accompanied by chronic infections. COPD has a prevalence of over 2% in the UK population (corresponding to approx. 1 million in the UK, probably a lower bound estimate due to many undiagnosed cases; this figure is approx. 16 million in the USA) and is currently the third biggest killer in the world (only behind cancers and heart-related diseases) – costing the lives of millions (in the USA alone, number of deaths attributed to COPD is over 100 thousand); and the health services, billions of pounds.
Contrary to the well-known genetic disorders such as Cystic Fibrosis and Huntington’s disease, which are diseases caused entirely by a person’s genetic makeup and caused by mutations in a single gene, COPD is a (very!) complex disease with many genes and environmental factors (e.g. smoking, pollutants) contributing to the development/progression of the disease. This complexity makes it much harder to dissect the causes and find potential (genetic) targets for cures or therapies. However, we do know that smoking is by far the biggest risk factor with up to 90% of those who go on to develop clinically significant COPD being smokers. But only a minority (<25%) of all smokers develop COPD, indicating the strong role genetics can play in the progression of this disorder. Also not all COPD patients are smokers (up to 25% in some populations), indicating that – at least in some patients – genetics can play a rather determining role. I must stress that all the statistics I provide here can vary considerably from population to population due to different lifestyles and genetic backgrounds.
I – together with a large group of collaborators – search for genetic predictors of lung function, which helps us to identify which individuals are more likely to develop the disease and potentially understand the underlying biology/pathology of respiratory diseases such as COPD and asthma, and related traits such as smoking behaviour. To do this, we carry out what is called a genome-wide association study (GWAS, click on link for details), where we obtain the genetic data (millions of data points) from tens of thousands of COPD (or asthma) patients and ‘controls’ (people with normal lung function). To ensure that our results are not biased by different ethnicities, life styles and related individuals, we collect all the relevant information about the participants and make sure that we control for them in the statistical models that we use. GWASs have been extremely successful in the identification of successful targets for other diseases and have led to the field of Genetic Epidemiology (GE, click on link for details) to come to the fore of population-based medicine. GE requires extensive understanding of Statistics (needed to make sense of the very large datasets), Bioinformatics (application of computer software to the management of large biological data), Programming (needed to change data formats, manage very large data), Genetics (needed for interpretation of results) and Epidemiology (branch of medicine which deals with how often diseases occur in different groups of people, and why); thus requires inter-disciplinary collaborations.
GWAS results are traditionally presented with a Manhattan plot (due to its resemblance of the city’s skyline) where the genetic variants corresponding to the dots above the top grey line (representing P-values less than 5e-8 i.e. 0.00000005) are usually followed up with additional studies to validate their plausibility. Image taken from Wikipedia (click on image to access source)
The inferences we make from these studies can shed light in to which genes and biological pathways play key roles in causing COPD. We then follow up these newly identified genes and pathways to analyse whether there are molecules which could be used to target these and be potential drugs for treating COPD patients. Our results can be of immense help to Pharmaceutical companies (and ultimately to patients), as many clinical trials initiated without genetic line of evidence have failed, costing the public and these companies billions of pounds.
As smoking is the biggest risk factor for respiratory diseases like COPD, I am – also with the contribution of many collaborators – in the process of analysing whether some people are more likely to start smoking, stop after starting, and smoke more than usual when they start smoking. The results can have huge implications as many people struggle to stop smoking, and when they do, research suggests that up to 90% (figure differs between populations) of them start to smoke again within the first year after quitting. Smoking is not only a huge contributor to the risk of developing COPD, but also to lung (biggest killer amongst all cancers), mouth, throat, kidney, liver, pancreas, stomach and colon cancer (not an exhaustive list). In the UK alone, these cancers cause the slow and painful death of tens of thousands, alongside a huge psychological and financial burden on the families and public resources.
The “lung” and the short of it (stealing a phrase thought up by my colleagues at the University of Leicester, click on link to see who they are) is that COPD is a disease that is going to affect many of us, and any useful finding which leads to cures and/or therapies could increase the life years of COPD patients and affect the lives of thousands of people directly, and millions indirectly (e.g. families of COPD sufferers, cost to the NHS). Finding targets to help people stop smoking can potentially have even bigger implications as many continue to smoke, despite huge efforts and funding allocated to smoking prevention and cessation.
A nice TED talk about the world of Data science and Genetic Epidemiology
If we were to ask a question like this to the public we would probably get an equal split between yes and no. Also many reasons will be given for the explanation of the answers. A question like this is a tough and a broad one; and must be approached by a consortium of Statisticians, Psychologists and Sociologists. However genetics can also have a say on this.
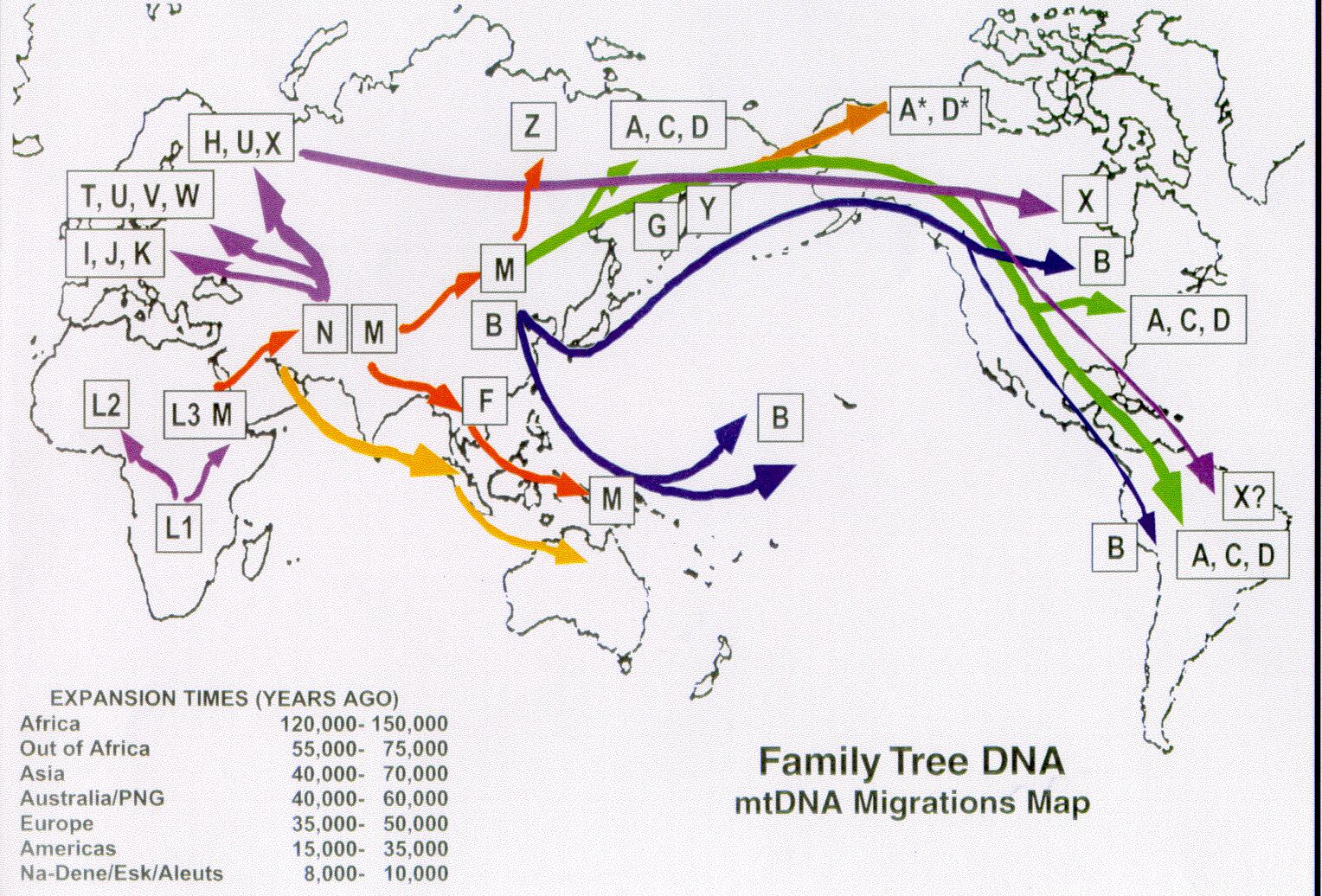
To come straight to the point: Mitochondrial DNA and the non-recombining regions of the Y chromosome can be used to determine the matrilineal and the patrilineal ancestry of an individual respectively. By analysing the variants in these uniparentally inherited DNA molecules people who shared a common ancestor many generations ago can be identified; and these individuals are usually clustered in ‘haplogroups’. Also by analysing the spread and frequency of haplogroups in different regions, we can deduce migrations and special events which occurred in human history.
When the spread of Y-DNA and mitochondrial (mtDNA) haplogroups are compared, we see that mtDNA haplogroups are more spread (and are less associated with a geographic region) than Y-DNA haplogroups indicating that women (who were our ancestors) in the past seems to have married more outside of their ethnic origin compared to males. This could probably be explained by the use of women when strengthening ties with other communities and monarchies in ancient times but the same might by said for males also. So (ancestral human) genetics gives some evidence towards the answer ‘yes’. More evidence from other fields are needed of course.
From what we read from the news, women from the poor parts of the world have a tendency to marry *foreign men for money and better life standards but there isn’t much statistical information on this, so cannot say anything definitive.
I suggest that scientists from different fields (like the above mentioned ones) come together and answer broad questions such as this; otherwise the correct answer will never be arrived at by a single field of science.
For more information about the use of genetics (i.e. mitochondrial DNA and Y chromosome) when deducing maternal and paternal ancestry:
Ben 12 yaşındayken (2000) ailecek İngiltere'ye taşındık ve ingilizcem neredeyse sıfırdı. Bunu duyan (Karen Holman adında) Sınıf Öğretmenim, kendimi evimde hissedeyim diye tüm arkadaşlarıma Türkçe cümleler dağıtmış. Sınıfa girer-girmez arkadaşlarımın hepsi bana "Hoşgeldin" dediler